如何加快语言模型的生成速度?
前言
当我们使用 ChatGPT、Claude 或 DeepSeek 这类语言模型时,有没有想过:模型是怎么一个字一个字「吐」出来的?为什么有时候反应很快,有时候又很慢?
语言模型的使用过程称为推理(Inference)。本质上,模型在做「文字接龙」——给定一段输入,预测下一个 token 应该是什么,然后把这个 token 再当作输入,预测再下一个,如此循环。
今天主流的语言模型都基于 Transformer 架构,其核心机制是 Self-Attention。它的作用是让模型在生成每一个 token 时,都能考虑到整个输入序列的信息。
但这也带来了性能瓶颈。怎么加速?
一、Flash Attention:少搬资料,快如闪电
Self-Attention 的计算逻辑
在介绍 Flash Attention 之前,先回顾 Self-Attention 的计算过程。
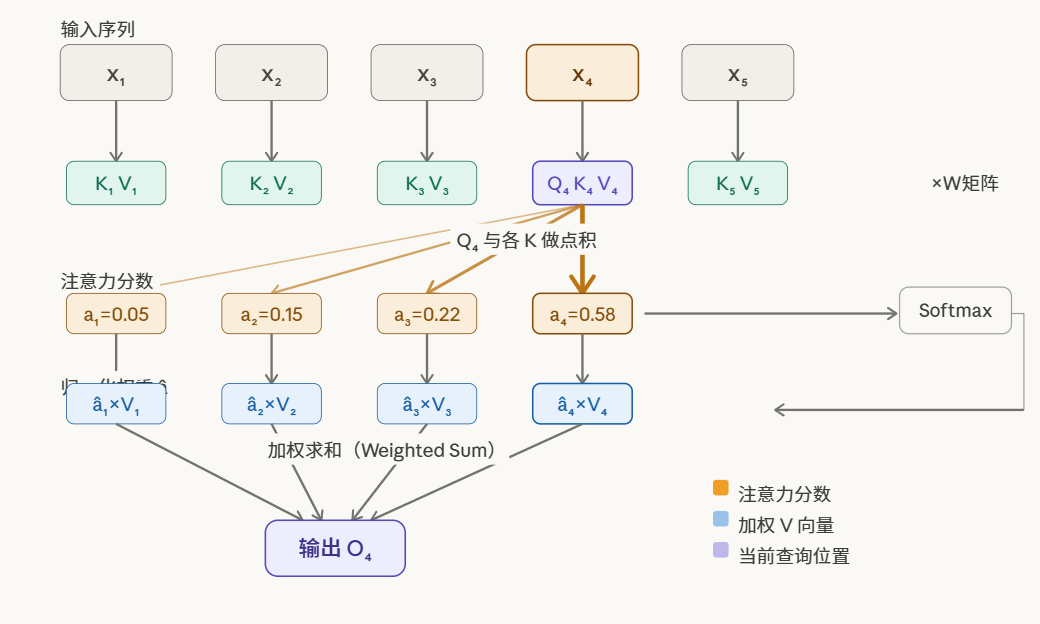
给定输入序列,每个位置的向量会被变换为三个角色:Query(Q)、Key(K)、Value(V)。
以生成第 4 个位置的输出为例:
- 用 Q4 和前面所有的 K 计算点积,得到注意力分数 $a_1, a_2, a_3, a_4$
- 对注意力分数做 Softmax 归一化,得到 $\hat{a}_1 \sim \hat{a}_4$
- 对所有 V 做加权求和,得到输出 $O_4$
这个过程看起来简洁,但一旦序列变长(比如十万、百万个 token),中间涉及大量数据的读写,速度就会成为瓶颈。
GPU 的工作原理:工作台与仓库
理解 Flash Attention,需要先了解 GPU 的底层逻辑。
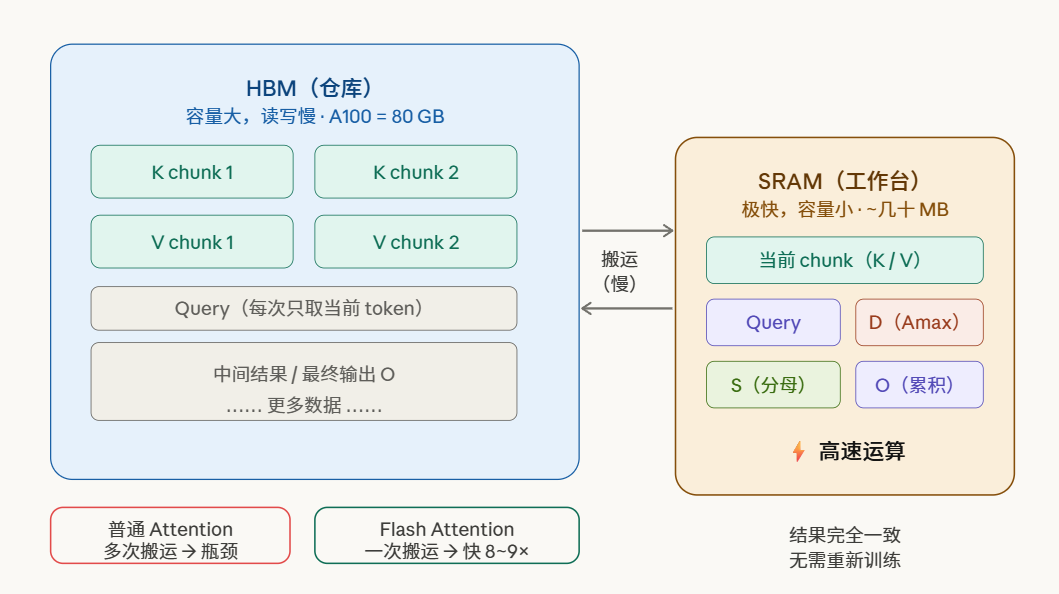
GPU 内部有两个关键的存储区域:
| 存储区域 | 对应硬件 | 特点 |
|---|---|---|
| 工作台 | SRAM(片上缓存) | 极快,但容量极小(约几十 MB) |
| 仓库 | HBM(显存) | 容量大(如 A100 有 80GB),但读写较慢 |
运算单元(Execution Unit)只能在工作台上做计算。所有数据都存在仓库里,需要搬到工作台才能运算,算完再搬回去。
搬运数据,才是真正的速度瓶颈。
普通 Attention 的问题
在计算 Softmax 归一化时,我们需要知道所有注意力分数的最大值 $a_{max}$(为了防止数值溢出),还需要把所有分数的指数值加总作为分母。
这意味着需要多次把大量数据在工作台和仓库之间来回搬运:
- 第一遍:扫描所有分数,找出 $a_{max}$
- 第二遍:计算所有 $e^{a_i - a_{max}}$
- 第三遍:对所有 $e^{a_i - a_{max}}$ 求和,得到分母
- 第四遍:计算最终的 $\hat{a}_i$
- 再做一遍加权求和……
每一「遍」都意味着大量数据进出仓库,极其低效。
Flash Attention 的核心思想
Flash Attention(2022 年提出)的精髓是:
改变计算顺序,减少搬运次数,一步到位得到最终输出 O。
具体做法是将 K 和 V 分成若干个小 chunk,每次只把一个 chunk 搬到工作台上,同时把 Q 也搬上来,在工作台上完成所有运算——包括当前 chunk 的加权求和。
关键在于:即使当前 chunk 里计算的 $a_{max}$ 和分母都是「错的」(因为还没看完所有数据),Flash Attention 也能在后续 chunk 处理时对前面的结果进行精确修正,最终保证输出 O 与标准 Attention 完全一致。
整个过程中,注意力权重矩阵 $\hat{a}$ 从来没有被完整计算出来——直接跳过,得到最终结果 O。
这也导致一个「副作用」:如果你尝试用 Hugging Face 读取 Flash Attention 模型的注意力权重,会直接报错——因为它根本没被存下来。
Flash Attention 的效果
在 A100 GPU 上测试,使用随机生成的 Q、K、V:
- 序列长度 4096 时,Flash Attention 比朴素实现快约 8~9 倍
- 计算结果与标准 Attention 的最大误差在 $10^{-7}$ 量级,几乎无差异
更重要的是,Flash Attention 不改变 Attention 的计算结果,无需重新训练模型,随插即用。如今使用 PyTorch 的 scaled_dot_product_attention,默认就已经开启 Flash Attention。
代价:算法实现较为复杂,有少量额外计算。仅此而已。
二、KV Cache:存下算过的,下次直接用
语言模型的两个阶段
语言模型生成文字分为两个阶段:
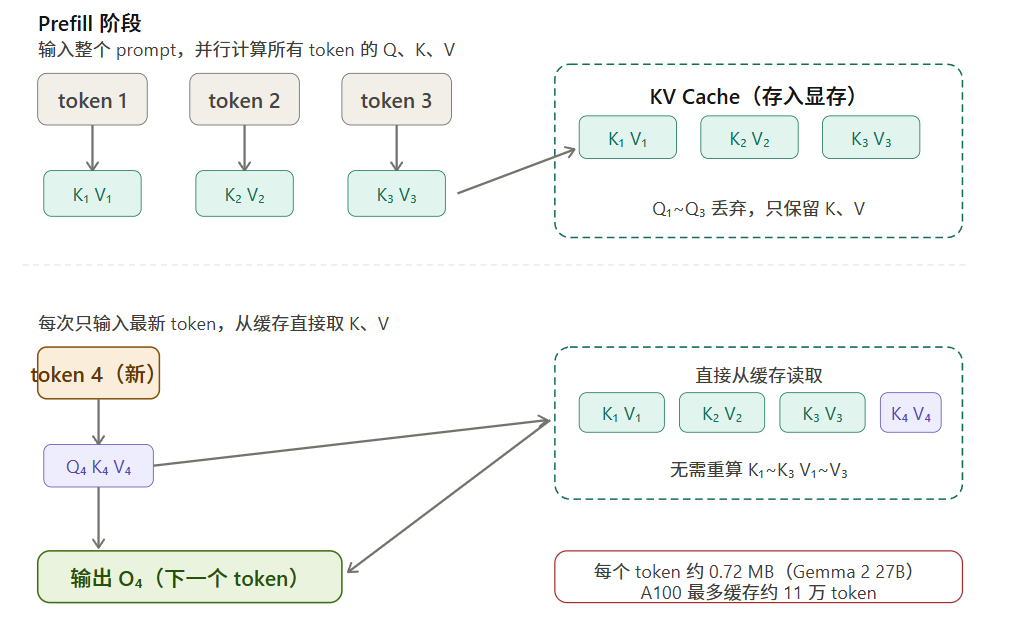
Prefill(预填充):将用户输入的整个 prompt 一次性送入模型,并行计算所有 token 的 Q、K、V,得到第一个输出 token。
KV Cache 的核心逻辑
每生成一个新 token(比如第 5 个),它需要和之前所有 token(第 1~4 个)的 K、V 计算 Attention。
如果每次都重新计算 K1K4 和 V1V4,实在太浪费了——这些值在 Prefill 阶段已经算好了,不会改变。
解决方案就是 KV Cache:把每个 token 对应的 K 和 V 存入显存。之后每次只需计算新 token 自己的 Q、K、V,旧的直接从缓存里取。
注意:Q 不需要存,因为每次只用当前 token 的 Q,用完即弃。
KV Cache 有多占空间?
以 Gemma 2(27B 模型) 为例:
- 46 层 × 16 个 KV Head × 128 维 × 2 字节(FP16)× 2(K+V)
- 每生成一个 token,需要约 0.72 MB 显存
看起来不大,但 A100 的 80GB 显存算下来,满打满算只能存约 11 万个 token。而现实中的 AI Agent 常常需要处理远超 10 万 token 的上下文——这就是「CUDA Out of Memory」的由来。
三、KV Cache 的系列优化方案
为了让 KV Cache 占用更少显存,研究者们想出了各种办法。
1. Multi-Query Attention(MQA)
传统的 Multi-Head Attention(MHA)中,每个 Head 都有独立的 K 和 V。
MQA 的想法是:所有 Query 共用同一组 K 和 V。这样 K、V 的数量从多组变成一组,显存占用大幅下降。
但代价明显:实验表明 MQA 会明显损害模型能力。
2. Grouped-Query Attention(GQA)
GQA 是 MHA 和 MQA 之间的折中方案:多个 Query 共享一组 K 和 V,但 K、V 不只有一组。
例如 4 个 Query 分成 2 组,每组共用一对 K、V。既减少了显存,又保留了较好的模型能力。
LLaMA、Gemma 等主流模型均采用 GQA。
3. Multi-Head Latent Attention(MLA)
MLA 的思路更巧妙:将多组 K、V 压缩成一个低维向量 C 存储。
神奇之处在于,计算 Attention 时无需先解压缩 C:
- 计算点积时,可以把 Q 先变换到压缩空间,直接与 C 做点积,数学上等价于解压后再计算
- 计算加权和时,直接在压缩的 C 上做加权求和,最后只解压缩一次即可
这样既省了显存,又避免了大量解压缩运算。DeepSeek 模型便使用了这一技术,且效果甚至略优于标准 MHA。
4. Sliding Window Attention(滑窗注意力)
每个 token 只 Attend 前面固定窗口范围内的 K、V(例如 4096 个),超出范围的直接忽略。
优点是 KV Cache 的大小有了固定上限。
缺点是理论上无法直接处理超长序列,但由于 Transformer 有多层,通过层层传递,感受野仍然可以很大。Mistral 7B 的某些版本使用了该技术。
5. Streaming LLM
在滑窗注意力的基础上,始终保留序列最开头的几个 token 的 K、V,即使它们已经超出窗口范围。
研究发现,语言模型在 Attention 时非常依赖序列的第一个 token——这是模型学到的一种「我没什么好关注的时候,就 Attend 第一个 token」的行为。
一旦失去第一个 token,模型表现会急剧下降;加回来,立刻恢复正常。Streaming LLM 甚至不需要重新训练模型即可应用。
6. KV Cache Pruning(剪枝)
研究发现,大量 K、V 在整个生成过程中几乎从未被 Attend 到,白白占用显存。
代表性工作 Scissorhands 和 H2O 发现:只需保留少数「热门」K、V(被反复 Attend 的 token),丢弃其余,在很多任务上几乎不影响效果。
Scissorhands 甚至测试了只保留 20% 的 K、V(压缩 5 倍),在多项任务上表现与全量 KV Cache 相当。
但难度较高的任务仍然对此比较敏感,相关研究仍在持续深入。
四、跨对话的 KV Cache 复用
KV Cache 不仅可以在单次对话内复用,还可以跨对话复用。
原理很简单:如果两个不同的输入有相同的前缀(Prefix),那么这段前缀对应的 K、V 是完全一样的,可以直接复用。
这正是各大平台「Cache Input」折扣的来源。以 GPT-4o 为例,命中缓存的输入 token 可以享受约 10% 的原价(即九折优惠)。
实际影响有多大? 2025 年 1 月的一项研究表明,在 Gemini 2.5 Pro 和 GPT-4o 上,合理利用 Cache Input 可节省 50% 甚至更多 的调用成本。
如何最大化 Cache Hit?
关键是让 稳定不变的内容放在 Prompt 前面,变化的内容放在后面。
以 AI Agent 的 System Prompt 为例:
- 放前面:工具列表、Agent 身份与目标(这些几乎不变)
- 放后面:当前日期、用户具体请求(这些每次都在变)
一旦前面的内容发生变化,整个缓存就会失效,折扣也随之消失。
Claude 的 System Prompt 在设计时也考虑了这一点——最稳定的工具配置信息被放在了最前面。
五、总结对比
| 方法 | 核心思路 | 改变原有 Attention? | 需要训练? | 其他代价 |
|---|---|---|---|---|
| Flash Attention | 减少数据搬运次数 | 不改变 | 不需要 | 少量额外计算,算法复杂 |
| KV Cache | 存储已算出的 K、V | 不改变 | 不需要 | 占用显存 |
| Multi-Query Attention | 所有 Query 共享 K、V | 改变 | 需要 | 可能明显损害模型能力 |
| Grouped-Query Attention | 部分 Query 共享 K、V | 改变 | 需要 | 略微损害,可接受 |
| Multi-Head Latent Attention | 压缩 K、V | 改变 | 需要 | 实际效果反而可能更好 |
| Sliding Window Attention | 限制 Attention 范围 | 改变 | 可选 | 超长序列处理能力受限 |
| Streaming LLM | 保留头部 token | 改变 | 可选 | — |
| KV Cache Pruning | 丢弃无用 K、V | 改变 | 不需要 | 难任务上可能损害能力 |
| Speculative Decoding | 用小模型加速大模型 | 理论不改变 | 不需要 | 需额外小模型算力 |
写在最后
从 Flash Attention 到 KV Cache,每一项技术都在用各自的方式回答同一个问题:如何在有限的硬件资源下,让语言模型跑得更快、服务更多人。
这些看似底层的工程优化,实际上深刻影响着我们每一次与 AI 对话的体验——也决定着背后的算力成本与商业可行性。
理解它们,不只是为了技术本身,更是为了看清 AI 系统的全貌。